
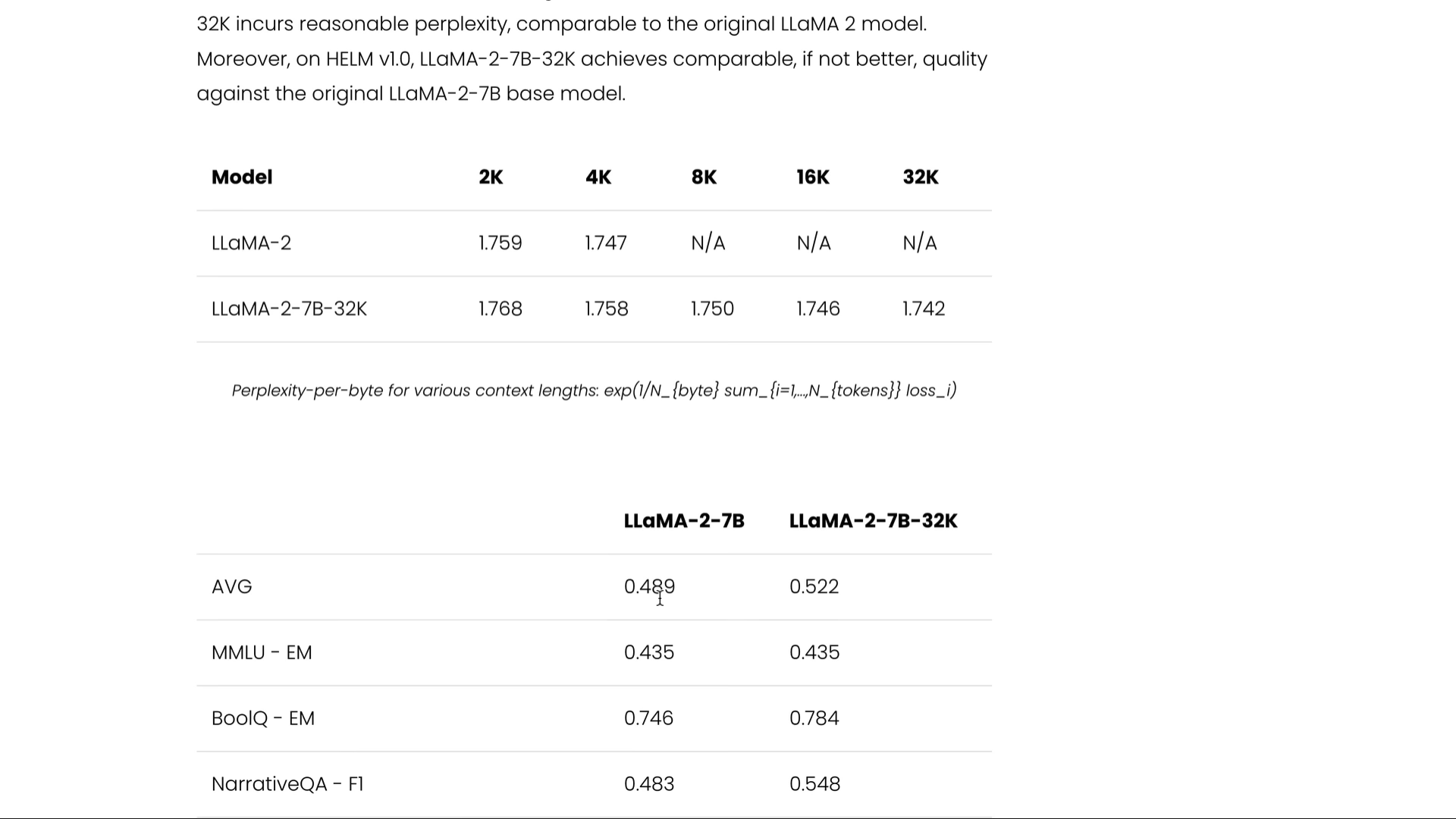
Medium
Im referencing GPT4-32ks max context size The context size does seem to pose an issue but Ive. Llama2 has double the context length Llama2 was fine-tuned for helpfulness and safety. All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion tokens and have. I thought Llama2s maximum context length was 4096 tokens When I went to perform an. In Llama 2 the size of the context in terms of number of tokens has doubled from 2048 to 4096. LLaMA-2 has a context length of 4K tokens To extend it to 32K context three things need to come. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models. The model has been extended to a context length of 32K with position interpolation allowing applications on..
Download Llama 2 encompasses a range of generative text models both pretrained and fine-tuned with sizes from 7. Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70. Chat with Llama 2 70B Clone on GitHub Customize Llamas personality by clicking the settings button. Llama 2 70b stands as the most astute version of Llama 2 and is the favorite among users. Llama 2 Purple Llama Code Llama. This repository is intended as a minimal example to load Llama 2 models and run inference. Under Download custom model or LoRA enter TheBlokeLlama-2-70B-chat-GPTQ. Llama 2 pretrained models are trained on 2 trillion tokens and have double the context length than Llama 1..
Code Llama is a family of state-of-the-art open-access versions of Llama 2 specialized on code tasks and were excited to release. Code Llama This organization is the home of the Code Llama models in the Hugging Face Transformers format Code Llama is a code-specialized version of. Llama 2 is being released with a very permissive community license and is available for commercial use. The code of the implementation in Hugging Face is based on GPT-NeoX here The original code of the authors can be found here. To deploy a Codellama 2 model go to the huggingfacecocodellama relnofollowmodel page and..
Jose Nicholas Francisco Published on 082323 Updated on 101123 Llama 1 vs Metas Genius Breakthrough in AI Architecture. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in. Most of the pretraining setting and model architecture is adopted from Llama 1. The LLaMA-2 paper describes the architecture in good detail to help data scientists recreate fine-tune the models. Ranjan Subramanian Xiaoqing Ellen Tan Yuchen Zhang Melanie Kambadur Aurelien Rodriguez Guillaume WenzekFrancisco Guzmán In this..

Medium




Comments